

1、项目背景
为通过项目实战增加对知识图谱的认识,几乎找了所有网上的开源项目及视频实战教程。
果然,功夫不负有心人,找到了中科院软件所刘焕勇老师在上的开源项目,基于知识图谱的医药领域问答项目。
项目地址:
用了两个晚上搭建了两套,Mac版与版,哈哈,运行成功!!!
从无到有搭建一个以疾病为中心的一定规模医药领域知识图谱,以该知识图谱完成自动问答与分析服务。该项目立足医药领域,以垂直型医药网站为数据来源,以疾病为核心,构建起一个包含7类规模为4.4万的知识实体,11类规模约30万实体关系的知识图谱。 本项目将包括以下两部分的内容:
1、基于垂直网站数据的医药知识图谱构建
2、基于医药知识图谱的自动问答 2、项目环境 2.1 系统
搭建中间有很多坑,且行且注意。
配置要求:要求配置neo4j数据库及相应的依赖包。neo4j数据库用户名密码记住,并修改相应文件。
安装neo4j,neo4j 依赖java jdk 1.8版本以上:
java jdk安装方法可参考: 系统下安装JDK8,下载地址:
安装neo4j可参考博文: 安装neo4j,下载地址:
安装可参考: 环境下安装.7
根据neo4j 安装时的端口、账户、密码配置设置设置项目配置文件:.py&.py(下载项目时根据个人需要也可使用git)
数据导入: .py,导入的数据较多,估计需要几个小时。
.py导入数据之前,需要在该文件main函数中加入:
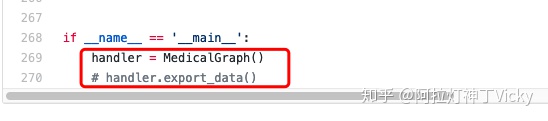
.py
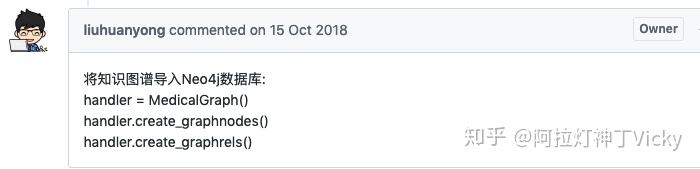
启动问答: .py
2.2 Mac系统
mac本身自带、java jdk环境,可直接安装neo4j图数据库,项目运行步骤与基本一样。
问题解答:
安装过程中如遇问题可联系: -sbb。 2.3 Neo4j数据库展示
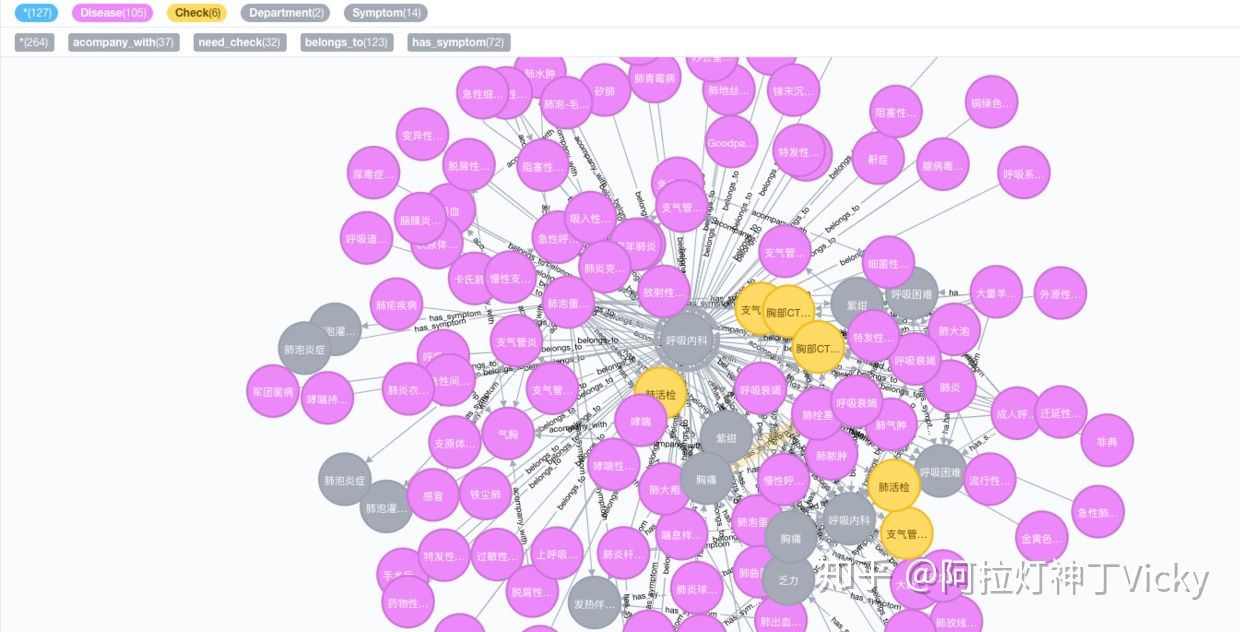
2.4 问答系统运行效果

3、项目介绍
该项目的数据来自垂直类医疗网站寻医问药,使用爬虫脚本.py,以结构化数据为主,构建了以疾病为中心的医疗知识图谱,实体规模4.4万,实体关系规模30万。的设计根据所采集的结构化数据生成,对网页的结构化数据进行xpath解析。
项目的数据存储采用Neo4j图数据库,问答系统采用了规则匹配方式完成,数据操作采用neo4j声明的。
项目的不足之处在于疾病的引发原因、预防等以大段文字返回,这块可引入事件抽取,可将原因结构化表示出来。
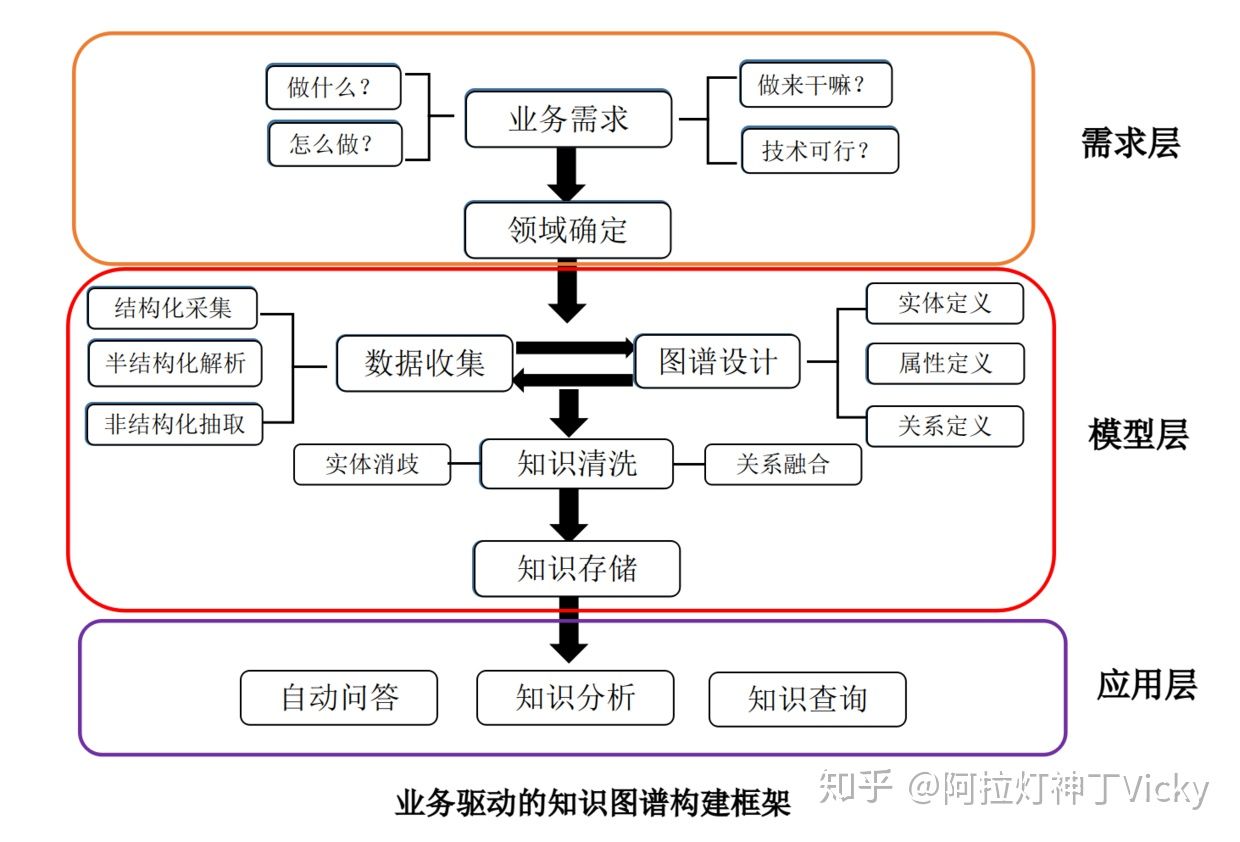
3.1 项目目录
.
├── README.md
├── __pycache__ \\编译结果保存目录
│ ├── answer_search.cpython-36.pyc
│ ├── question_classifier.cpython-36.pyc
│ └── question_parser.cpython-36.pyc
├── answer_search.py
├── answer_search.pyc
├── build_medicalgraph.py \\知识图谱数据入库脚本
├── chatbot_graph.py \\问答程序脚本
├── data
│ └── medicaln.json \\本项目的全部数据,通过build_medicalgraph.py导neo4j
├── dict
│ ├── check.txt \\诊断检查项目实体库
│ ├── deny.txt \\否定词库
│ ├── department.txt \\医疗科目实体库
│ ├── disease.txt \\疾病实体库
│ ├── drug.txt \\药品实体库
│ ├── food.txt \\食物实体库
│ ├── producer.txt \\在售药品库
│ └── symptom.txt \\疾病症状实体库
├── document
│ ├── chat1.png \\系统运行问答截图01
│ ├── chat2.png \\系统运行问答截图01
│ ├── kg_route.png \\知识图谱构建框架
│ ├── qa_route.png \\问答系统框架图
├── img \\README.md中的所用图片
│ ├── chat1.png
│ ├── chat2.png
│ ├── graph_summary.png
│ ├── kg_route.png
│ └── qa_route.png
├── prepare_data
│ ├── build_data.py \\数据库操作脚本
│ ├── data_spider.py \\网络资讯采集脚本
│ └── max_cut.py \\基于词典的最大向前/向后脚本
├── question_classifier.py \\问句类型分类脚本
├── question_classifier.pyc
├── question_parser.py \\问句解析脚本
├── question_parser.pyc3.2 知识图谱的实体类型
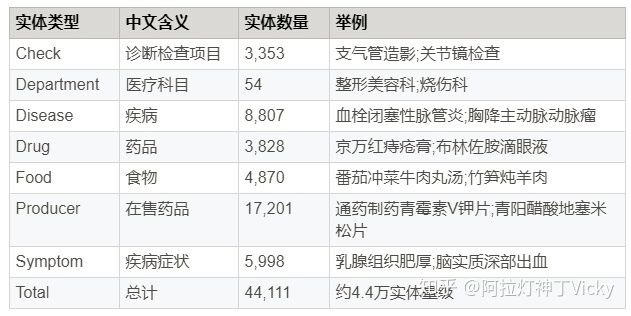
3.3 知识图谱的实体关系类型
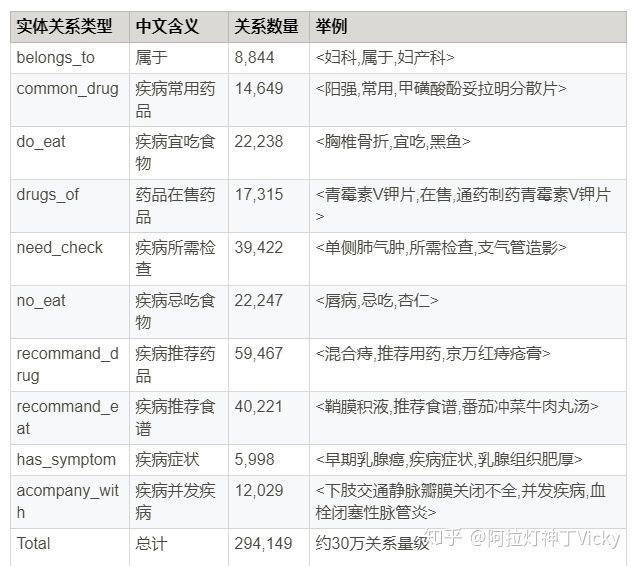
3.4 知识图谱的属性类型
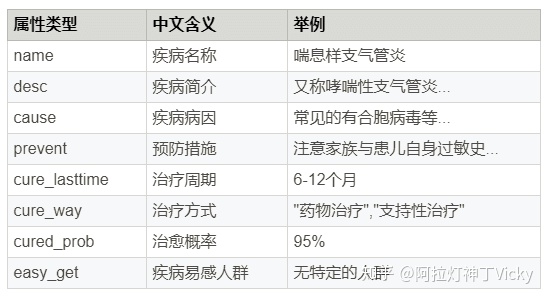
3.5 问答项目实现原理
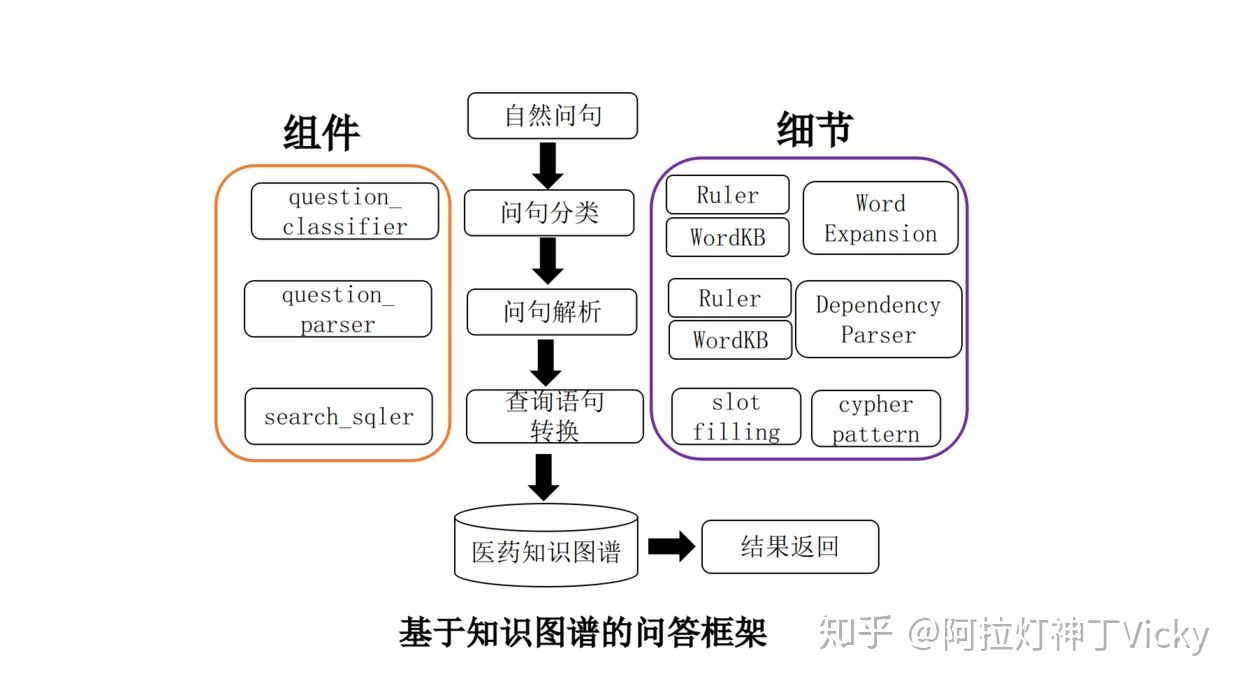
本项目的问答系统完全基于规则匹配实现,通过关键词匹配,对问句进行分类,医疗问题本身属于封闭域类场景,对领域问题进行穷举并分类,然后使用的match去匹配查找neo4j,根据返回数据组装问句回答,最后返回结果。
问句中的关键词匹配:

根据匹配到的关键词分类问句
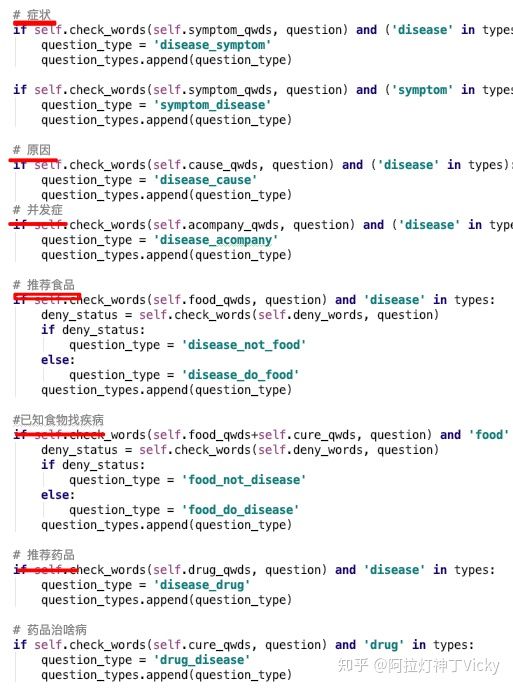
问句解析

查找相关数据

根据返回的数据组装回答

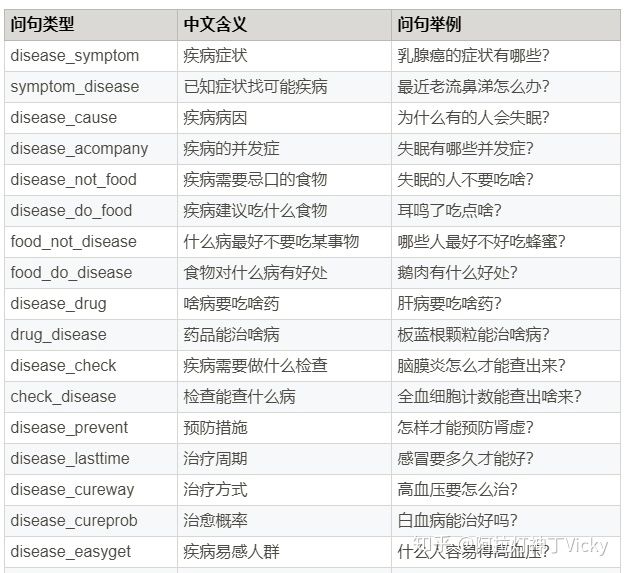
3.6 问答系统支持的问答类型
4、项目总结
基于规则的问答系统没有复杂的算法医疗问答系统,一般采用模板匹配的方式寻找匹配度最高的答案,回答结果依赖于问句类型、模板语料库的覆盖全面性,面对已知的问题,可以给出合适的答案,对于模板匹配不到的问题或问句类型,经常遇到的有三种回答方式:
1、给出一个无厘头的答案;
2、婉转的回答不知道,提示用户换种方式去问;
3、转移话题,回避问题;
例如,本项目中采用了婉转的方式回答不知道:

基于知识图谱的问答系统的主要特征是知识图谱,系统依赖一个或多个领域的实体医疗问答系统,并基于图谱进行推理或演绎,深度回答用户的问题,基于知识图谱的问答系统更擅长回答知识性问题,与基于模板的聊天机器人有所不同的是它更直接、直观的给用户答案。对于不能回答、或不知道的问题,一般直接返回失败,而不是转移话题避免尴尬。
整个问答系统的优劣依赖于知识图谱中知识的数量与质量。也算是利弊共存吧!知识图谱图谱具有良好的可扩展性,扩展了知识图谱也就是扩展了问答系统的知识库。如果问句在射程范围内,可轻松回答,但如果不幸脱靶,则体验大打折扣。
 鄂ICP备2024042591号-1
鄂ICP备2024042591号-1
 工商网监 电子标识
工商网监 电子标识