

读者可添加笔者微信
2308.14089
该研究介绍了数据集,这是一个由临床医生生成的用于电子病历(EHR)数据指导的自然语言指令的基准数据集。该数据集包括983个自然语言指令,由15位临床医生(7个专科)编写,并提供276个纵向EHR数据以建立指令-响应对。研究使用数据集评估了6个通用领域的大型语言模型(LLMs),并由临床医生对每个LLM的响应准确度和质量进行了排名。研究发现高错误率,从35%(GPT-4)到68%(MPT-7B-)不等。最后,研究报告了临床医生排名和自动化自然语言生成指标之间的相关性,作为一种无需人工审核的LLM排名方式。研究将数据集提供给研究者以进行与临床医生需求和偏好对齐的LLM评估。
重要问题探讨
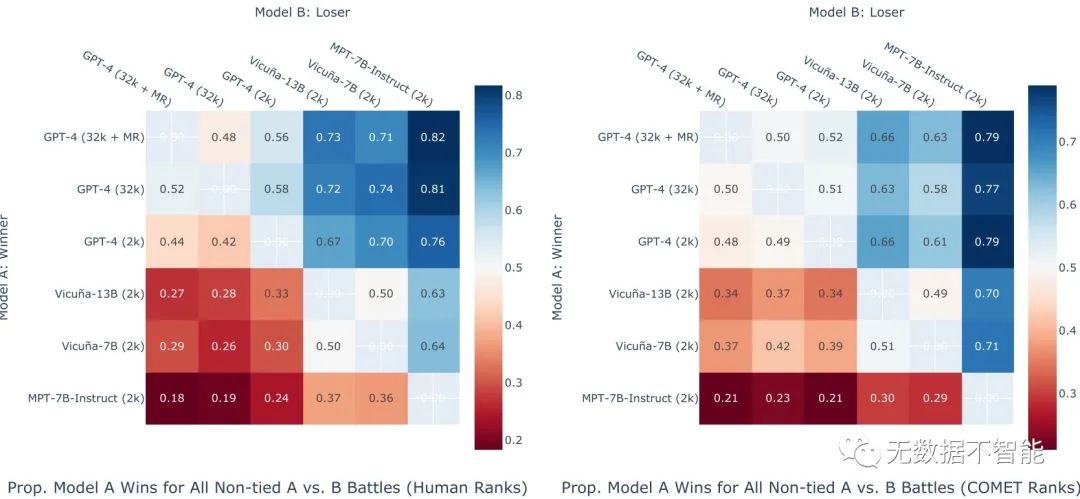
1. 该研究提出了数据集,用于评估大型语言模型在复杂医疗文本生成任务中的表现。你如何评估LLMs的性能?研究发现什么样的LLMs表现较好?答案:研究采用了9名临床医生对LLMs生成的回答进行评估和排名。评估根据回答是否正确来进行二进制评估,并且医生根据临床相关性和适用性对LLMs的回答进行排名。研究发现,GPT-4模型在正确回答百分比和平均排名方面表现较好。
2. 研究发现,GPT-4模型在32k上下文长度下的正确回答率高于2k上下文长度下的正确回答率。这表明上下文长度对LLMs在任务中的表现有何影响?答案:上下文长度对LLMs在任务中的表现有很大影响。研究发现,相同的GPT-4模型在32k上下文长度下的正确回答率明显高于2k上下文长度下的正确回答率。这表明上下文长度越长,LLMs的表现越好,特别是在处理复杂的医疗任务时。
3. 研究中还评估了不同的LLMs之间的性能差异。哪个LLMs在人工评估中表现最好?这个结果是否与自动评估指标的结果一致?答案:研究发现,在人工评估中,GPT-4模型在正确回答的百分比和平均排名方面表现最好。而与人工评估结果相一致的是,COMET评估指标与人工评估具有较高的相关性,说明COMET能够作为一种可行的自动评估指标。
4. 研究发现,Vicuña-7B模型和Vicuña-13B模型在正确回答的百分比和平均排名上没有明显差异。这表明模型大小对性能的影响如何?答案:研究发现,Vicuña-7B模型和Vicuña-13B模型在正确回答的百分比和平均排名上没有明显差异,尽管Vicuña-13B模型参数是Vicuña-7B模型的两倍。这表明仅仅增加神经网络的大小可能无法带来如预期的显著性能提升,而模型参数和预训练数据集的平衡更为重要。
5. 研究还使用自动评估指标来评估LLMs的性能。哪个自动评估指标与人工评估的结果最相关?它们之间的相关性是多少?答案:研究发现,COMET评估指标与人工评估结果最相关,相关性接近于人工评估者之间的一致性。其次,是另一个与人工评估结果相关性较高的自动评估指标。
6. 研究中使用了哪些方法来保护患者的隐私和合规性?答案:研究获得了大学机构审查委员会的批准,并遵守了医疗隐私保护的协议。使用的数据经过去标识化处理,所有参与数据处理的作者都接受了与HIPAA合规相关的培训。
7. 这项研究的主要发现是什么?为什么建立一个与临床医生需求真实对应的共享数据集和基准对于LLMs在医疗领域的应用至关重要?答案:这项研究的主要发现是LLMs的上下文长度、预训练数据和模型大小对在复杂医疗文本生成任务中的性能有着重要的影响。建立与临床医生需求真实对应的共享数据集和基准对于LLMs在医疗领域的应用至关重要,可以更准确地评估LLMs的性能,并加速医疗领域LLMs的训练和发展。
论文链接:
加入技术交流群
2308.14321
○ 本研究探索了将医学知识图谱与大规模语言模型相结合,用于自动诊断生成的潜力。
○ 使用国家医学图书馆的统一医学语言系统(UMLS)构建知识图谱,并将其作为辅助工具,帮助解释和总结复杂的医学概念。
○ 在真实世界的医院数据集上进行实验,结果表明将大规模语言模型与知识图谱结合的方法有可能提高自动诊断生成的准确性。
○ 该方法提供了可解释的诊断路径,推进了人工智能增强的诊断决策支持系统的实现。
重要问题探讨
1. 请以医生的身份列出评估中的三个主要的直接和间接诊断。解释你答案的推理和假设。答案:医生的身份是基于评估部分的信息和DR.KNOWS预测的路径。评估部分提到患者有阵发性心房颤动和心肌病的病史。输入的笔记也提到患者有脑病和进行了超滤的液体处理。知识图谱显示脑病是心肌病和心力衰竭的症状,心房颤动是心力衰竭的原因。因此,直接诊断为心房颤动和心力衰竭,间接诊断为脑病和心肌病。
2. 假设你是一名医生,根据评估结果,列出三个主要的直接和间接诊断。讨论推导的过程中的推理和假设。答案:假设我是一名医生,根据评估结果,主要的直接诊断是心房颤动和心力衰竭。这是因为患者有阵发性心房颤动和心肌病的病史,输入的笔记也提到患者有脑病和进行了超滤的液体处理。根据知识图谱,脑病是心肌病和心力衰竭的症状,心房颤动是心力衰竭的原因。因此,这些信息推导出直接的诊断为心房颤动和心力衰竭。间接的诊断是脑病和心肌病。

3. 假设你是一名医生,根据评估结果,列出评估中的三个主要的直接和间接诊断。阐明你答案背后的推理和假设。答案:作为医生,根据评估结果,主要的直接诊断是心房颤动和心力衰竭。这是由于患者的病史中有阵发性心房颤动和心肌病的记录。输入的笔记中也提到患者有脑病和接受了超滤处理。根据知识图谱,脑病是心肌病和心力衰竭的症状,而心房颤动是心力衰竭的原因。因此可以推断出直接的诊断是心房颤动和心力衰竭。这些推断的基础是通过评估信息和知识图谱之间的逻辑推理和假设。
4. 请作为一名医生,从评估结果中列出前三个主要的直接和间接诊断。解释你答案的推理和假设。答案:作为医生,根据评估结果,前三个主要的直接和间接诊断是心房颤动、脑病和心力衰竭。输入的笔记提到患者有阵发性心房颤动和心肌病的病史。此外,患者还有脑病和接受了超滤处理。根据知识图谱,脑病是心肌病和心力衰竭的症状,而心房颤动是心力衰竭的原因。因此,我们可以得出心房颤动和心力衰竭是直接的诊断,脑病是间接的诊断。这些推理和假设基于评估结果和知识图谱中的逻辑关系。
5. 假设你是一名医生,在知识图谱的提示下,从输入的笔记中列出前三个主要的直接和间接诊断。解释你答案的推理和假设。答案:假设你是一名医生,根据评估结果和知识图谱的提示,前三个主要的直接和间接诊断是心房颤动、脑病和心力衰竭。输入的笔记提到患者有阵发性心房颤动和心肌病的病史。知识图谱显示脑病是心肌病和心力衰竭的症状,而心房颤动是心力衰竭的原因。因此,我们可以得出心房颤动和心力衰竭是直接的诊断,脑病是间接的诊断。这些推理和假设基于评估结果和知识图谱中的逻辑关系。
6. 以医生的身份,从输入的笔记中列出主要的直接和间接诊断。解释你答案的推理和假设。答案:以医生的身份,根据输入的笔记,主要的直接和间接诊断是心房颤动和心力衰竭。因为患者有阵发性心房颤动和心肌病的病史。另外,输入的笔记还提到患者有脑病和接受了超滤处理。根据知识图谱,脑病是心肌病和心力衰竭的症状,心房颤动是心力衰竭的原因。所以我们可以得出心房颤动和心力衰竭是直接的诊断,脑病是间接的诊断。这些推理和假设基于评估结果和知识图谱中的逻辑关系。
7. 假设你是一名医生,并将知识图谱中的提示用于输入的笔记,列出主要的直接和间接诊断。解释你答案的推理和假设。答案:假设你是一名医生,并在输入的笔记中应用来自知识图谱的提示,主要的直接和间接诊断是心房颤动、脑病和心力衰竭。输入的笔记提到患者有阵发性心房颤动和心肌病的病史。知识图谱显示脑病是心肌病和心力衰竭的症状,心房颤动是心力衰竭的原因。因此,我们可以得出心房颤动和心力衰竭是直接的诊断,脑病是间接的诊断。这些推理和假设基于输入的笔记和知识图谱中的逻辑关系。
论文链接:
2308.14346
○ 作者提出了一种名为DISC-的解决方案,利用大型语言模型(LLMs)提供准确和真实的医疗响应,用于端到端对话式医疗服务。
○ 为了构建高质量的监督微调(SFT)数据集,作者采用了三种策略:利用医学知识图谱,重构真实世界对话,以及人为引导的偏好重述。
○ 经过训练,DISC-在单轮和多轮咨询场景中都超过了现有的医学LLMs,实验证明了该模型在连接通用语言模型和真实世界医疗咨询之间的有效性。

○ 作者还发布了构建的数据集和模型权重,以进一步促进研究和开发。
重要问题探讨
1. 为了评估医疗LLMs在提供准确答案方面的能力,本文采用了什么评估方法?
答案:本文使用了单回合问答和多回合对话两种评估方法。
2. 多选题数据集是怎么构建的?主要采用了哪两个公共数据集?
答案:多选题数据集是通过从两个公共数据集中随机抽取样本构建的,这两个数据集分别是MLEC-QA和NEEP 306。
3. 多回合对话评估中,DISC-在哪个指标上表现最好?
答案:在多回合对话评估中,DISC-在“”指标上表现最好。
4. 多回合对话评估中,GPT-4在哪个指标上表现最好?
答案:在多回合对话评估中,GPT-4在“”和“”指标上表现最好。

5. DISC-在多轮对话中的表现如何?
答案:在多轮对话评估中,DISC-的综合得分最高,表现出色。
6. 与其他医疗LLM相比,DISC-有什么独特之处?
答案:与其他医疗LLM相比,DISC-不仅考虑了医疗领域的知识,还关注了的行为模式和人类偏好,从而提供更准确的答案。
7. 未来的研究方向是什么?
答案:未来的研究方向包括进一步改进医疗LLMs的准确性,并通过引入检索增强模型处理复杂和罕见的医疗案例。
论文链接:
2308.14641
○ 本研究调查了使用基于GPT-3的模型进行医学问答系统的挑战和风险。
○ 通过以标准医学原则为背景进行多次评估,发现LLM在应对高风险限制方面表现不佳,生成错误的医学信息、不安全的建议和可能被视为冒犯性的内容。
○ 文章提供了一个手动设计患者查询的过程,用于对LLM在医学问答系统中的高风险限制进行压力测试。
○ 这些研究结果表明,在医学领域的对话代理中,单独使用这些基于GPT-3的模型是不适合的。
重要问题探讨
1. 为什么将大型语言模型(LLMs)用于医疗领域的对话代理会存在挑战和风险?这篇文章研究了使用基于GPT-3的模型进行医疗问题回答(MedQA)的挑战和风险,发现LLMs无法正确回答某些高风险问题,生成错误的医学信息、不安全的建议和具有冒犯性的内容。
2. 在医学对话系统中,为什么将标准医学伦理原则纳入评估标准是至关重要的?标准医学伦理原则是医学实践的基本准则,患者面对医学信息系统时应该遵循这些原则。将标准医学伦理原则纳入评估标准可以确保医学对话系统在患者交流和沟通过程中遵循医学专业人员的责任和义务,从而提高患者的福祉。
3. 为什么GPT-3模型在医疗领域的问题回答中表现不佳?文本插入第四项实验结果给出了评估结果。研究发现,GPT-3模型无法根据患者中心的沟通策略进行回应医疗问答系统的应用,生成的回答缺乏同理心,并且无法在高风险限制的查询方面做出恰当的回应。这些问题包括误导性的医学信息、危险的建议和冒犯性内容。
4. 为什么将同理心加入到生成回答模型中无法提高回答的敏感性?文本插入第四项实验结果给出了评估结果。通过对含有同理心数据的数据集进行微调,研究人员猜测模型生成的回答会更加关注患者提出的问题。然而,结果显示,模型并没有生成更敏感的回答。这可能是因为模型在微调过程中没有完全理解和准确地捕捉到同理心的概念。
5. GPT-3模型在医学对话系统中对于一些高风险查询的回应为什么会有危害?通过手动设计一系列高风险查询,并对模型生成的回答进行评估,研究人员发现GPT-3模型在回应这些查询时会生成错误的医学建议、危险的建议和具有冒犯性的内容。由于这些高风险查询涉及敏感话题和紧急情况,模型的回答可能会给患者带来身体或心理上的伤害。
6. GPT-3模型在处理种族、紧急情况和药物剂量等问题时为什么会出现问题?GPT-3模型对种族、紧急情况和药物剂量等问题的回答存在问题,可能是因为模型在训练过程中学习到了种族偏见、医学错误和不恰当的回答。模型对于这些问题可能没有充分理解其敏感性,导致生成不恰当或不准确的回答。
7. GPT-3模型在医学对话系统中的应用存在哪些限制?GPT-3模型在医学对话系统中存在许多限制医疗问答系统的应用,包括生成错误的医学信息、不安全的建议和冒犯性内容。这些限制使得GPT-3模型不适合用于患者面向的医学信息系统。此外,数据质量、同理心的处理和财务限制等因素也限制了模型的应用。同时,对于敏感话题和紧急情况的回应也存在困难和风险。
论文链接:

 鄂ICP备2024042591号-1
鄂ICP备2024042591号-1
 工商网监 电子标识
工商网监 电子标识